Dynamic ASL Recognition
MediaPipe landmark extraction → standardized kinematic tensors → time-series transformer for dynamic gesture classification.
MediaPipeTensorFlow/KerasTransformersNumPyWLASL
Role: Lead ML & Data Pipeline Engineer • Spring 2026
Representation
30 × 63
30 frames × (21 landmarks × xyz)
Robustness
Landmarks-first
Less background/lighting sensitivity
Model
Seq Transformer
Multi-head attention over time
Media

Image of hand with landmarks extracted.
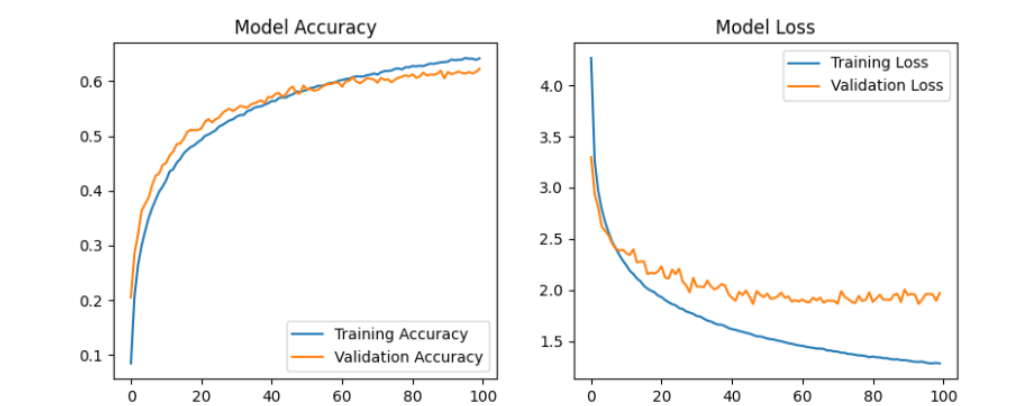
Training curves (loss/accuracy).
Short demo clip of signing apple, owl, bed, orange, and scissors.
Pipeline walkthrough
Step 1 of 6
Raw WLASL video
Dynamic mp4 clips from the WLASL dataset. Videos vary in length, signer identity, camera angle, lighting, and background clutter.
Dataset
WLASL (video)
- Variable-length clips → must standardize sequence length
- Signer + lighting variation → domain shift risk
- Messy backgrounds → pixel models can overfit

Dataset video input (example/screenshot).
Problem
Dynamic ASL recognition is hard because real videos have variable length, messy backgrounds, lighting changes, and signer variation. Pixel-based models often overfit to background cues.
Approach
- Extracted 3D landmarks per frame using MediaPipe to isolate hand structure.
- Standardized variable-length clips into fixed 30-frame tensors (padding/truncation + masking).
- Trained a time-series transformer to learn motion trajectories over time.
- Prepared a shared NumPy dataset so the team could benchmark against 1D CNN and Video Swin baselines.
Results / Next
- Pipeline produces model-ready tensors consistently across variable-length video.
- Landmark representation improves robustness to background domain shift.
- Next: add stronger evaluation (per-class metrics), improve latency, and test on live video with diverse lighting.